Motivation:
The motivation behind the self supervised learning is to learn general feature representations from the input data, with no labels, and then fine tune such representations on a different task using a few labels.
- In self supervised learning, the model is not trained using a label as a supervision signal, but using the input data itself.
A sample use case: Training a model to predict a hidden part of an input, given an observed part of the same input.
Below you can see the differences between supervised and self-supervised learning.

Why do we need self-supervised learning schemes?
- One major issue with the pure supervised learning problem is the need for tremendous labeled training data, which in some cases is impossible to find. Self supervised learning reduces the necessity of annotating and finding labeled data and hence it saves time, and money.
- Unlabeled data is everywhere, one can literally scrape the web and collect different format of input data, audio, video, images, etc.
More Examples:
Now, let’s present some examples of self-supervised learning to better illustrate how it works.
1. Visual
A lot of self-supervised methods have been proposed for learning better visual representations. As we’ll see below, there are many ways that we can manipulate an input image so as to generate a pseudo-label.
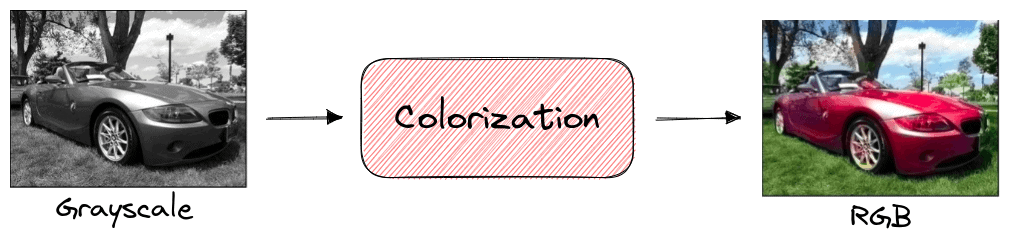
In image colorization, a self-supervised model is trained to color a grayscale input image. During training, there is no need for labels since the same image can be used in its grayscale and RGB format. After training, the learned feature representation has captured the important semantic characteristics of the image and can then be used in other downstream tasks like classification or segmentation:

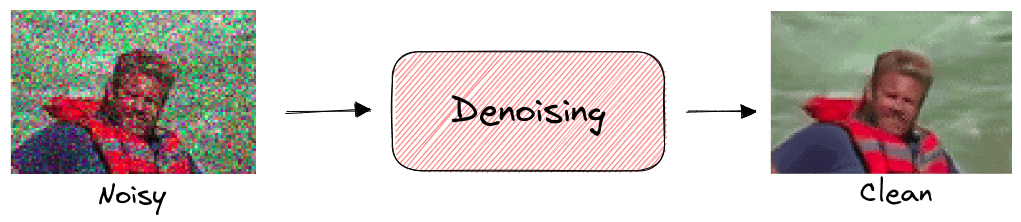
Another task that is common in self-supervision is denoising where the model learns to recover an image from a corrupted or noisy version. The model can be trained in a dataset without labels since we can easily add any type of image noise in the input image:
In image inpainting, our goal is to reconstruct the missing regions in an image. Specifically, the model takes as input an image that contains some missing pixels and tries to fill these pixels so as to keep the context of the image consistent. Self-supervision can be applied here since we can just crop random parts of every image to generate the training set:
2. Audio-Visual
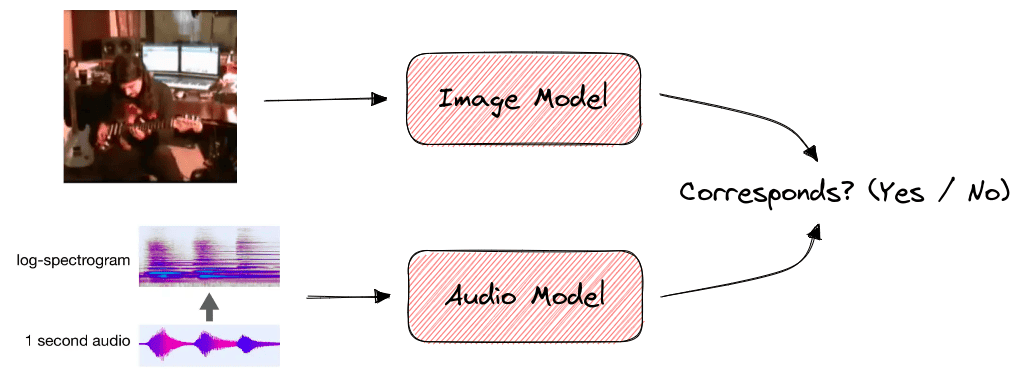
Self-supervised learning can also be applied in audio-visual tasks like finding audio-visual correspondence.
In a video clip, we know that audio and visual events tend to occur together like a musician plucking guitar strings and the resulting melody. We can learn the relationship between visual and audio events by training a model for audio-visual correspondence. Specifically, the model takes as input a video and an audio clip and decides if the two clips correspond to the same event. Since both the audio and visual modality of a video are available beforehand, there is no need for labels:
3. Text
When training a language model it is very challenging to define a prediction goal so as to learn rich word representations. Self-supervised learning is widely used in the training of large-scale language models like BERT.
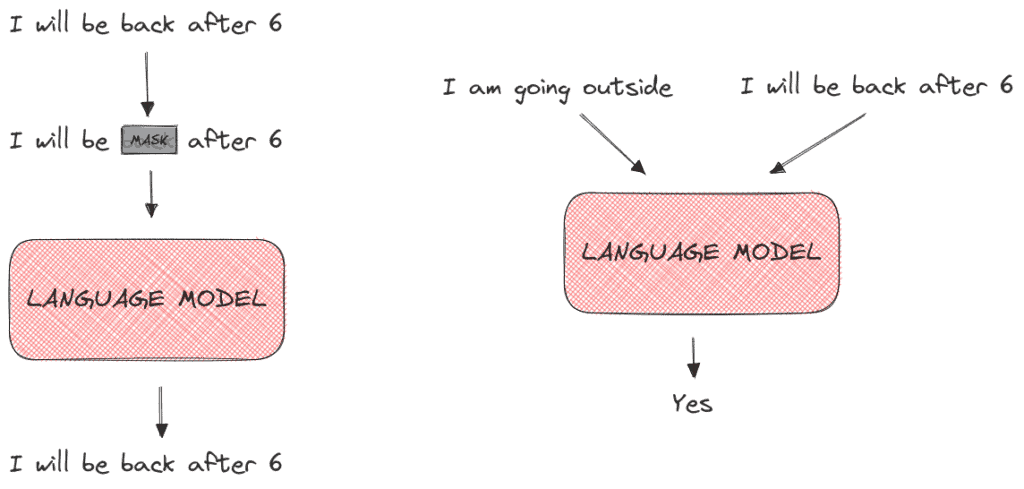
To learn general word representations without supervision, two self-supervised training strategies are used:
- MaskedLM where we hide some words from the input sentence and train the language model to predict these hidden words.
- Next Sentence Prediction where the model takes as input a pair of sentences and learns their relationship (if the second sentence comes after the first sentence).
Below, we can see an example of the MaskedLM (left) and the Next Sentence Prediction (right) training objectives:
Limitations
Despite its powerful capabilities, self-supervised learning presents some limitations that we should always take into account.
1. Training Time
There is already a lot of controversy over the high amount of time and computing power that the training of a machine learning model takes with a negative impact on the environment. Training a model without the supervision of real annotations can be even more time-consuming. So, we should always compare this extra amount of time with the time it takes to just annotate the dataset and work with a supervised learning method.
2. Accuracy of Labels
In self-supervised learning, we generate some type of pseudo-labels for our models instead of using real labels. There are cases where these pseudo-labels are inaccurate hurting the overall performance of the model. So, we should always check the quality of the generated pseudo-labels